(作者:党博文)
6月1日,英伟达CEO黄仁勋在台北国际电脑展上宣布,其下一代AI超级芯片平台VeraRubin已全面投产,将于今年秋季开始发货。几乎在同一时间,2026世界智能产业博览会在天津举行,华为展出的Atlas 900 A3 SuperPoD昇腾384超节点正式落地天津武清区。而就在十天前,央视财经报道了我国最大规模科学智能计算集群在河南郑州投入使用,6万张国产AI加速卡正在高速运行,支撑着从气象预报到新材料研发的各类科研任务。
这三条看似独立的新闻,勾勒出全球算力产业竞争的最新图景。一边是英伟达继续引领全球高端算力技术迭代,另一边是中国算力产业正在加速崛起。
2025年是中国算力产业的一个关键节点。根据IDC发布的《2025年度中国云端AI加速器市场报告》,2025年中国AI加速卡总出货量约为400万张,其中国产厂商合计出货约165万张,市场份额约41%。与此前英伟达在中国市场占据约95%份额的格局相比,变化明显。
这一数字背后,是中国算力产业从“能不能造”到“能不能用”再到“好不好用”的阶段性跨越。但需要指出的是,“跨越”不等于“赶超”,在单卡性能、软件生态和供应链等维度,国产算力与国际领先水平仍有差距。
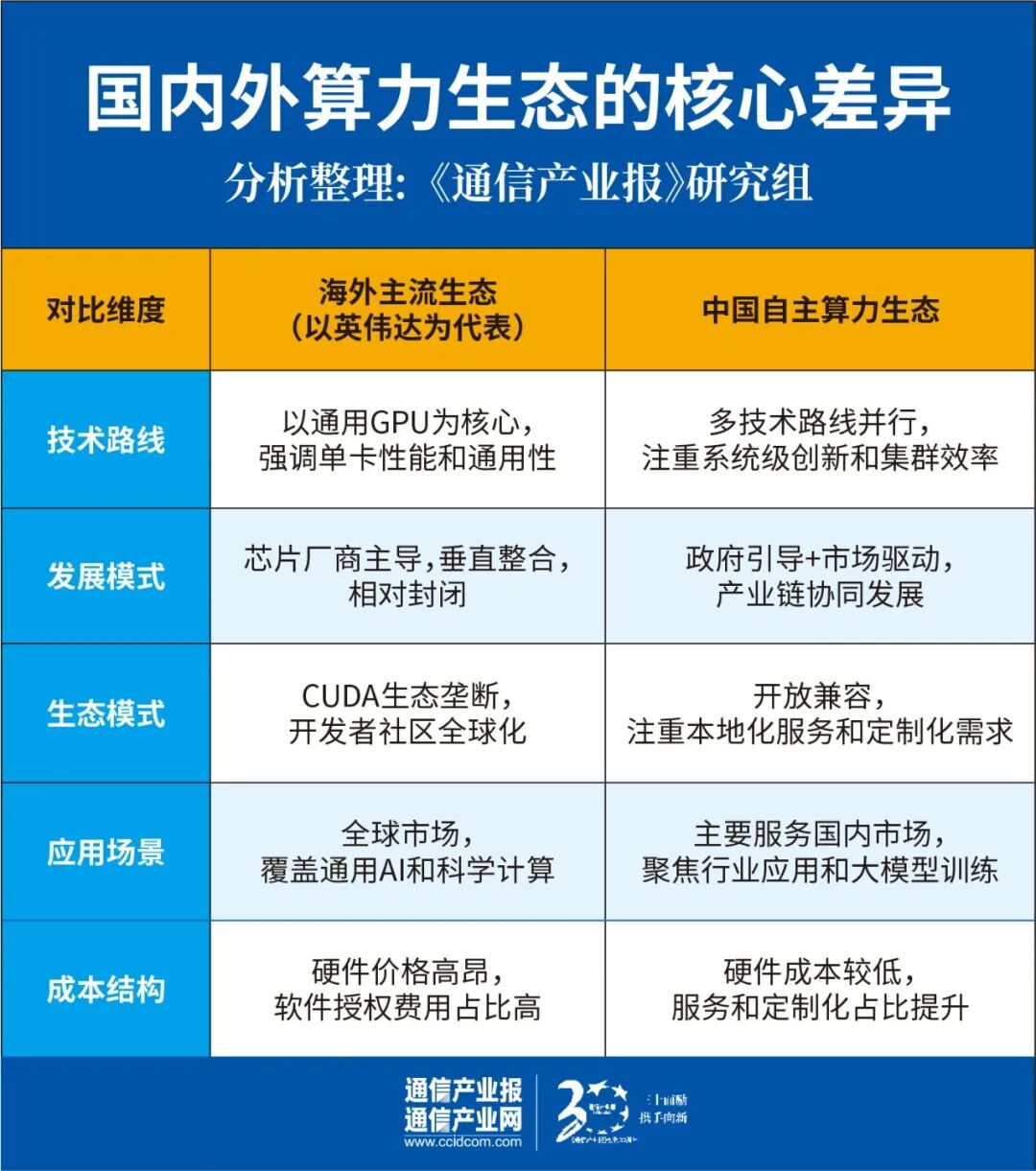
算力的竞争从来不是单卡的较量。英伟达的优势不仅在于GPU本身,更在于其围绕CUDA构建的完整软件生态和开发者社区。而国产算力走出了一条以系统换性能的差异化路径,在单卡性能存在差距的情况下,通过高速互联技术将多张芯片整合为统一的逻辑计算单元,以集群协同弥补单点不足。
2026年世界智能产业博览会期间,华为Atlas 900 A3 SuperPoD昇腾384超节点正式落地天津武清区。该超节点集成384颗昇腾NPU和192颗鲲鹏CPU,通过全对等高速总线互联,单集群BF16稠密算力达到300 PFLOPs,约为英伟达GB200 NVL72的1.7倍。
按照华为方面的数据,该超节点截至2025年9月已累计部署300多套,服务于互联网、金融、运营商、电力、制造等行业的20多个客户。这一系统架构创新,成为国产算力突围的重要方向。
与此同时,产业链上游也迎来重要进展。4月,我国最大规模科学智能计算集群在河南郑州的国家超算互联网核心节点投入使用,由6万张国产AI加速芯片组成,支撑从气象预报到新材料研发的各类科研任务。4月3日,粤港澳大湾区首个基于平头哥真武810E芯片的万卡智算集群在广东韶关正式上线,由中国电信广东公司与阿里云联合建设,计划扩容至10万卡规模。
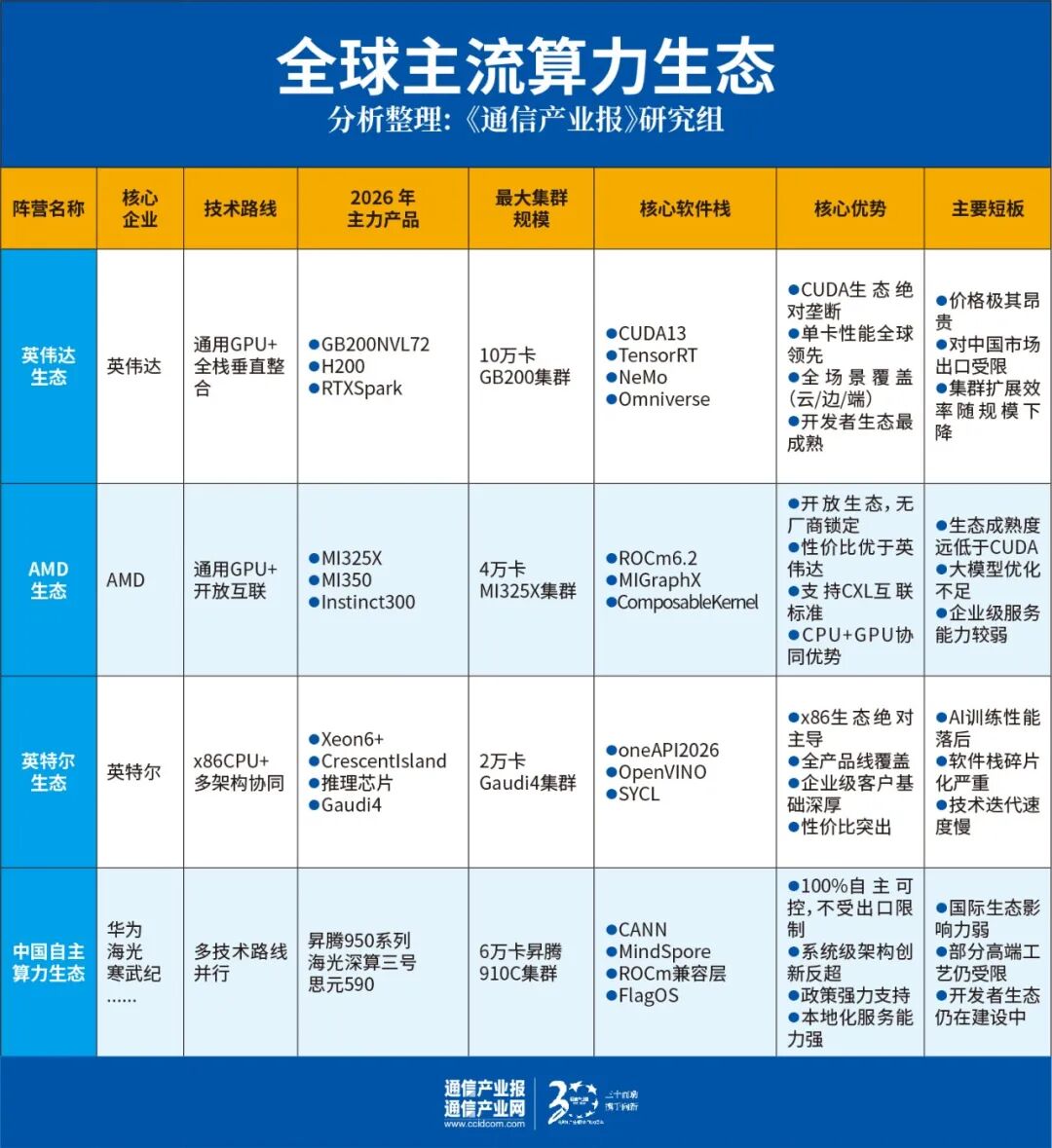
目前,全球算力产业已从英伟达“一超多强”的格局演变为多极化竞争态势。与海外主流算力生态相比,中国算力生态在技术路线和发展模式上呈现出鲜明的多元特色,不同厂商基于各自的技术积累和市场定位,走出了不同的发展道路。
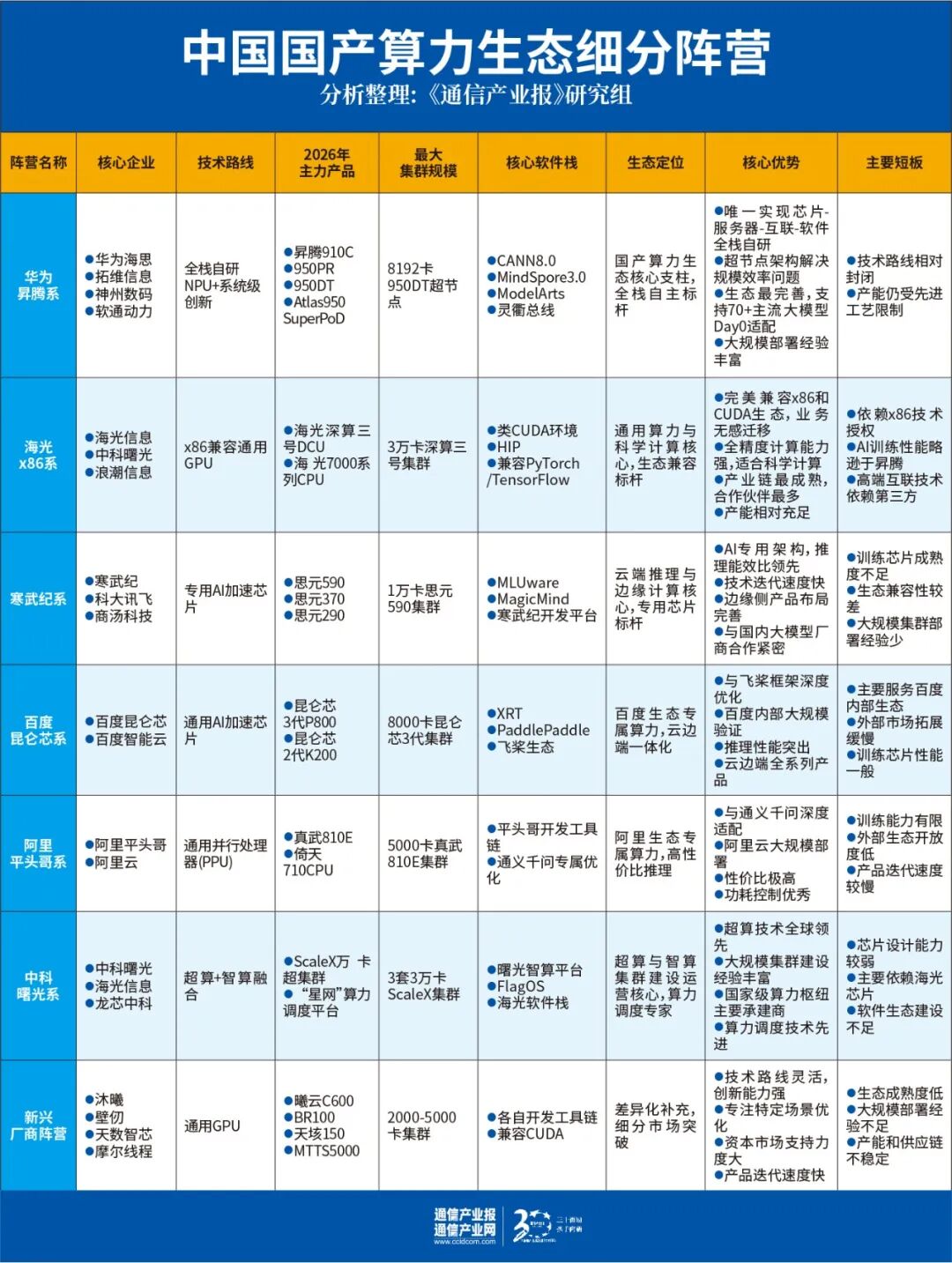
华为昇腾系是目前国产算力生态中技术布局最全面的阵营。华为实现了从芯片设计、服务器到互联技术、软件栈的全链条自研。昇腾超节点架构已成为国产大模型训练的主流方案之一。截至2025年5月,鲲鹏+昇腾生态已汇聚超过665万开发者、8800多家合作伙伴,完成23900多个解决方案认证。华为已开放灵衢互联协议2.0,支持产业伙伴构建基于该协议的超节点系统。
海光x86系提供了另一条技术路线。海光信息基于x86架构的DCU能够兼容CUDA生态,降低用户迁移成本。根据IDC数据,海光2025年AI加速卡出货量约8.3万张,市场份额约2%。在国产AI加速卡市场中,海光出货量占比约5%。
寒武纪系专注于云端推理和边缘计算领域。思元370已在阿里云推理场景中得到应用,截至2025年Q2承担了阿里云约60%的推理需求。思元590则于2026年初实现全场景规模出货。2025年寒武纪AI加速卡出货量约11.6万张,与百度昆仑芯并列国产第三。
百度昆仑芯系和阿里平头哥系依托各自的互联网生态,实现了算力与应用的深度融合。IDC数据显示,昆仑芯2025年出货量11.6万块,已成功点亮国内首个三万卡集群。昆仑芯计划2026年上市256卡互联的“天池256超节点”,2026年下半年推出512卡超节点。平头哥方面,截至2026年2月,自研AI芯片真武810E已累计规模化交付47万颗。海光DCU在科学计算和通用AI领域持续放量。
此外,中科曙光系在超算与智算集群建设运营方面经验丰富;沐曦、天数智芯等新兴厂商也在特定技术领域逐步放量。这种多元化的发展格局形成了相对良性的竞争环境,推动了算力产业的迭代和技术路径的探索。
尽管国产算力取得了阶段性进展,但客观来看,与国际先进水平相比仍存在明显差距。
一是单卡性能与国际顶尖水平仍有代差。英伟达下一代AI超级芯片平台Vera Rubin已于2026年6月宣布全面投产,秋季开始发货。根据此前披露的信息,Rubin平台在FP4精度下的推理性能较Blackwell提升5倍。预计2027年上半年推出的Vera Rubin Ultra将进一步形成新的性能压力。此外,HBM高带宽内存、先进封装等关键技术仍依赖进口,产能受到一定限制。
二是生态碎片化问题依然突出。国内各算力厂商采用不同的技术路线和软件栈,开发者需要针对不同平台进行适配。虽然华为已开放灵衢互联协议2.0,但整体而言,国产算力尚缺乏统一的软件标准和开发者生态。生态的碎片化影响了用户体验,也制约了国产算力的大规模推广。
三是推理算力正成为新的竞争焦点。TrendForce集邦咨询的研报显示,以北美五大CSP的整柜式方案估算,2026年AI推理算力年增约122%,而训练算力年增约56%,推理增速超过训练一倍以上。国产芯片在推理领域虽有一定基础,但在高并发、低时延等场景仍需进一步优化。
因此,在相关专家看来,面向未来,中国算力生态的持续发展需要在以下几个方向着力。
一是推动技术路线的开放与协同。华为开放灵衢互联协议是一个良好开端,未来应进一步推动软件栈的开放和标准化,减少生态碎片化带来的重复建设。
二是坚持应用驱动。中国拥有全球最大的AI应用市场,应鼓励算力厂商与行业用户深度合作,在自动驾驶、生物医药、智能制造等领域打造标杆应用,通过大规模应用带动技术迭代。
三是加强产业链协同创新。算力产业涉及芯片设计、制造、封装、测试、服务器、软件等多个环节,需要建立产业链协同机制,逐步突破HBM内存、高速光模块、先进封装等关键技术瓶颈。目前400G/800G光模块所需的100G EML芯片等核心器件仍高度依赖进口,国产化率约5%~20%。
四是稳步推进国际化布局。鼓励有条件的企业参与全球算力市场竞争,逐步提升国产算力生态的国际影响力。
2026年是中国算力产业发展的重要节点。经过多年积累,中国已建立起了相对完整的自主可控算力体系,打破了海外厂商在部分领域的垄断。算力产业的竞争是一场长期博弈。国产算力在系统架构创新和集群部署方面走在了前列,但在单卡性能、软件生态和供应链自主性等维度仍需持续突破。未来几年,如何在保持系统优势的同时补齐单点和生态短板,将决定国产算力能否实现从“并跑”到“领跑”的真正跨越。
推荐阅读





经典栏目
精彩专题
关注我们

大视频行业颇具影响力的行业社群平台,重要新闻、热点观察、深度评论分析,推动电视行业与各行各业的连接。

集合电视台、网络视听、潮科技等各种好玩信息。

专注于报道广电行业新鲜5G资讯,致力于成为广电行业有权威、有深度的5G自媒体平台。

UHD、4K、8K的最新资讯和最深入的分析,都在这里。

视频产业的专业圈子,人脉、活动、社区,就等你来。

我们只沉淀有深度的信息和数据。

致力于卫星电视信息、卫星通信技术、天地一体网络应用案例、以及广电、通信等产业的市场动态、政策法规和技术资讯的传播。














 关于我们
关于我们 诚聘英才
诚聘英才 商务合作
商务合作 中广圈子
中广圈子 意见反馈
意见反馈 关注我们
关注我们