高书生,中央宣传部文化体制改革和发展办公室原一级巡视员、副主任。2003年以来,参与文化体制改革总体文件和配套政策、文化产业振兴规划、文化产业促进法、文化产业统计标准、金融支持文化产业、文化和科技融合、文化数字化和文化大数据等文件制定,发表多篇文章,出版《感悟文化改革发展》、《文化数字化:关键词与路线图》等著作。
演讲内容正文
各位学界朋友,非常高兴受邀参加开幕式,今天我就文化数字化和文化元宇宙跟大家交流。
一、破题——从生产的角度探索文化元宇宙
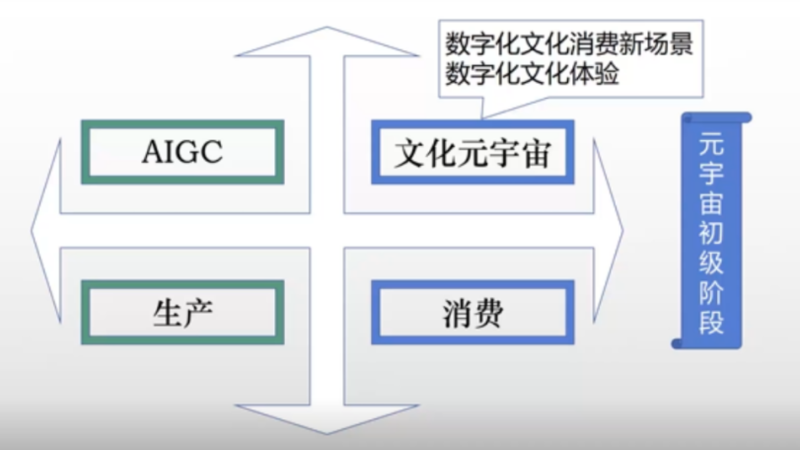
首先我觉得开幕式的主题很好,“开启文化元宇宙的新纪元”,我对这个主题的理解是从生产的角度探索文化元宇宙,这个意义非常大。因为目前这个阶段我们谈到“元宇宙”的时候,应该还是在消费层面,但今天这个标题是从生产的角度,不管是过去的PGC还是UGC一直到现在的AIGC,都是从不同的生产方式来讲的,这一点还是非常有启发性的。国家文化数字化战略就是从供给侧入手的,我们叫发力供给侧,激活文化资源,推动文化生产体系现代化。
就目前来说,在元宇宙的初级阶段,主要还是从消费层面做,也应是数字化文化消费的新场景,而且是数字化文化体验的一种形式。但我觉得再往前走,实际上已经进入到一个比较高的阶段了,实现生产和消费同一,这样来推动文化元宇宙的发展会更好一些,这是我对今天开幕式主题的理解。
二、数据——数字化时代的生产要素
现在大家都已经认为数据是数字化时代的一个生产要素,但我觉得现在叫“要素”的多,叫“生产要素”的不是太多。
1、数据保真:下一步人工智能发展的充分必要条件
从目前非常火的ChatGPT谈起,ChatGPT给我们的启示有两点,一个是数据如何保真,这个可能是大家非常关心的问题。可能是我工作岗位的原因,我们更多还是从管理的角度考虑问题,所以我们在想数据的保真可能是下一步人工智能发展一个非常重要的充分必要条件。如果说数据不能做到保真,人工智能发展的方向可能就会出现一些不应有的失误。
从各种讨论文章当中大家也都看到了,目前ChatGPT训练的数据集来源大体上分为六类,包括维基百科、书籍、期刊、互联网的网站等等,训练的数据集在GPT-3里面实际上总量应该有3000亿的词汇,有1750亿的参数,这给我们的触动是非常大的,如果没有这样一个数据量训练的话,人工智能发展确实有很大制约。

这段时间大家都在测试,都是在试新鲜,看看新的聊天机器人水平到底有多高,在这个过程中,可能有些人已经提出了一些问题。第一个大家比较关心的问题就是:互联网上的数据并不都是准确的,当错误的数据量足够大的时候,就会导致得出的结论也是错误的。有一个案例是基于GPT-3的医疗聊天机器人曾经建议病人自杀,这可能是个案,但如果个案多的话,就成了普遍性的了,归根结底就是数据的保真问题。而且现在所有的人工智能模型的学习都是基于一些历史数据,还有一些社会学学者也在研究,有可能这些数据当中存在不必要的偏见,这种偏见也会导致社会的排斥和歧视。所以说,扣好文化元宇宙第一粒扣子非常重要,我认为这是AIGC的充分必要条件,也是开发人工智能非常重要的条件。
这方面,跟我们现在正在推动实施的国家文化数字化战略有相通的地方。也就是这些数据集到底从哪里来,不光我们国人,国外也在问,在中文互联网的数据质量堪忧的情况下,我们的数据到底应该从哪里来?我们认为应该从中华民族积淀了五千多年的文化资源中转化而来,这可能是我们下一步应该重点考虑的。可能有人说你这个都是理论的东西,怎么变成现实?
其实在国家文化数字化战略当中,已经提出了非常明确的要求了。我国是文明古国,也是文化资源大国,这些年我们在推动文化数字化过程中,特别是文化资源数字化过程中,也积攒了大量的文化资源数据,这些数据大多数都集中在公共文化机构。所以说这次中办国办文件当中明确提出公共文化机构要向社会释放数据,要依法向社会公众开放,让大家都从这些数据当中提取具有历史传承价值的中华文化元素、符号和标识,并把它们转化为文化生产要素,从而就成为文化元宇宙,以及文化创新和创造的文化素材,这在国家文化数字化战略当中是非常明确的。
具体来说,我们现在数据量是非常大的,包括文化馆、图书馆、美术馆、博物馆。我们尤其关注的一个点是地方志,地方志的数据也是非常珍贵的。根据中国地方志指导小组统计,到2020年,我们省、市、县三级的地方志志书已经完成了有5000多部,到2020年底公开出版的已经有4900多部,同时现在又增加了一些部门志、行业志和专题志,这个数量就更大了,有25000多部。
同时像乡镇志、村志,还有过去的旧志,应该说这个量是非常大的。更重要的是这些年地方志的数字化已经有了一个长足的进展,截止到2019年年底,省、市、县三级光建成的数字方志馆(数据库)就有100多个,我估计现在会更多,像新华智云说已经有25个省、自治区和直辖市的数字方志馆。我们为什么用地方志呢,因为地方志是中华民族积淀5000年文化资源的底部,如果我们把地方志做通了,可能很多东西都可以做的。

还有就是文化旅游部下面有一个中国民族民间文艺发展中心,业内人认为这是一个文艺长城工程,大概是从“六五”时期开始做的,花用了三十年时间,动员了三十多万人的力量,最后收集到民族、民间的文艺资料是非常多的,总量应该是在50亿汉字左右,包括民歌、民间故事等等。现在已经出了很多书,也在推动进一步的数字化。还有一些中央新闻单位的数据量也是非常大的,例如人民日报、新华社、中央电视台、中央人民广播电台,还有国际台。我们出版业的数据也非常多,期刊里面有知网、万方、维普等,图书领域综合性的有国家数字图书馆,还有一些专业专题性的数据库也非常多。
同时,我们民间的数据量也非常大,为什么说是民间的,实际上从1983年、1984年开始,钱钟书老先生曾经开辟了一项事业,就是对中国古典文献做数字化,他在世的时候做了17年,去世以后这项工程又持续了二十多年,他们有个公司叫“扫叶”,现在积累的汉字数总量在20亿左右,其中汉字库是目前我们看到的最全的。我们知道《康熙字典》最多是4万多字,现在据说他们已经达到了将近8万个汉字,收录了36万人,比《中国人名大辞典》多出5倍,这里面有作品库、地名库,还有一些工具库、图片库、地图库等等,这个量也是非常大的。包括我们中华书局也在做相应古籍的整理,这个量也是很大的。

再看看有些地市级也在做大量的数据库,包括陕西渭南有一个“两河一山”文化数字记忆项目,他们积攒的数据库就有十个,包括重点文物保护、古代的书院、民间传说、诗词歌赋、历史文化名城、名镇、名村、名人数据库、非遗数据库、古籍目录数据库、传统戏曲剧目剧本数据库,还有红色文化资源数据库,有10个数据库,量还是非常非常大的。所以说,我们现在在推动实施国家文化数字化战略过程中的一项重要任务,就是关联形成中华文化数据库,这对整个人工智能的发展,通过人工智能创造生产更多面向大众的文化数字内容而言,是一个基础性的工程。
我们现在讲数据驱动,这个数据应该是具有文化内涵的数据,现在数据量非常大,但还没有去做标注、标引,那文化内涵是体现不出来的。我们过去经常说一句话“基础不牢,地动山摇”,现在我们许多产业项目、在推广的很多东西,包括互联网大厂在做的一些事,总的感觉是在沙漠上盖高楼,地基不稳,什么事都做不大。所以为什么人家说,ChatGPT没有在中国产生,我觉得这就是因为我们基础不牢。
2、数据标注:把数据的采集、加工和数据服务变成一种经常性的工作
第二个启示,就是数据的标注。有专家向ChatGPT提出:“请模仿杜甫写一首诗”,结果并不是很理想,因为呈现并不好。有的专家分析,在它的语料库中没有对汉语的韵律、字节做标注和训练,这可能是非常重要的原因。我们有了数据但不去做标注,那人工智能也发展不起来。对于数据的标注,我们这次在国家文化数字化战略当中有了一个明确的要求,就是希望各级各类文化机构,要把数据的采集、加工和数据服务变成一种经常性的工作。
数据的标注主要是从三个方面着手,第一要对数据进行分类,我们现在按照联合国教科文组织分的六大类别,包括自然和文化遗产、表演和庆祝活动、视觉艺术和手工艺、图书和出版、视听和互动传媒、设计与创意服务六大类别,然后在这个基础上,每个类别里都有一些专题的知识图谱,我们就可以依据它来做编目。分类和编目,实际上对数据定下坐标了,最后我们还要对数据的特征进行描述,即数据的标签化。
在这方面,我们国家这几年有了长足的进展,例如百度在全国有七个已经建成的数据标注基地,我去看过其中一个在山西太原的基地,当时我还没有什么感觉,去年突然间发现这是一个非常非常大的产业。山西太原这个基地是入驻在山西的综改示范区,到2022年的5月份,办公面积已经超过19000平米,有5000名数据标注师,有53家代理商入驻,从2018年进驻到2020年5月份,累计的产值已经超过5个亿,累计培育孵化了41家的数据标注企业。
文化领域的里面也有,同时我也参观了中国知网在太原的数据加工基地,他们是对期刊和报纸,包括一些论文做标注,而且这个量也是非常大的。刚才我们说太原的百度基地,每年的营收应该在1个亿左右,中国知网的太原数字出版数据加工基地营收也是在一年1个亿左右,这个量也是非常大。因此我们今年就想,在全国建设国家文化大数据标识基地,在标注的基础上再赋标识符(ISLI码),使具有文化内涵的数据,真正能够在国家文化专网互联互通,这是一项基础性工作。
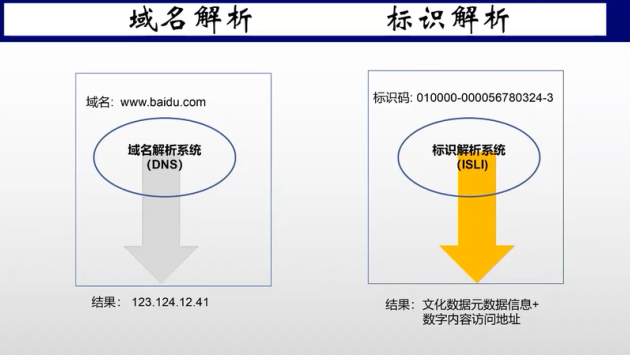
在这儿,我想多解释几句,我们用的标识是我国提案创建的国际标准,叫ISLI,就是国际信息和文献领域关联标识符的国际标准。我们现在文化数字化采用的是标识解析,这跟互联网的域名解析有很大的区别。区别在哪里呢?我们的域名解析是把域名变成了IP地址,用IP寻址的方式来解析。文化数字化用标识解析,用我们国家提案并创建的国际标准,为每一个数据赋标识码,然后我们自己有一套解析系统。它跟域名解析最大的区别是,我们标注的标识码后面都包含两个主要内容,一个是数据的元数据信息,一个是数据的访问地址。
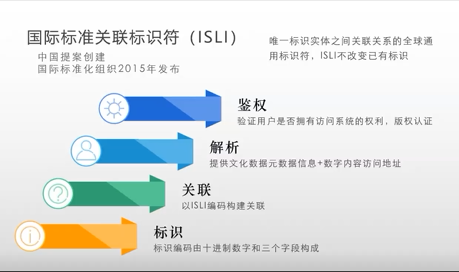
这样的话,这个国际标准就发挥它的四大功能:第一就是标识,标识编码由十进制的数字和三个字段构成的;第二用这个码构建数据和数据之间的关联关系,这一点非常重要,这也是国际信息和文献领域当中唯一一个具有关联功能的国际标准;第三就是它的解析功能;第四是鉴权功能,验证用户是不是拥有访问系统的权利,也即版权的认证,这些问题我们全解决了,在数字化时代,所有数据涉及到的版权问题,用标识解析就可以解决。
这样就达到了三个目的:第一是数据的互联互通,因为它有地址和元数据;第二是数据的分布式存储,现在的文化机构最大的问题是担心自己的数据被别人盗取,所以我们一方面先用了国家文化专网,跟互联网是物理隔离的,同时我们也采用了标识解析,可以实现物理分布、逻辑关联,即谁的数据还是在谁的服务器里,或者数据中心里面,但是由于它可以互联互通,别人知道你有数据,然后可以进行交易,通过授权使用用这个数据来做加工;最后一个是数据的确权,每个数据都有唯一的身份证,而且是伴随着这个数据的全生命周期,从采集、加工、生产、交易到最后数据的呈现全过程,以及它和其它的数据融为一体之后所产生的新的文化数字内容,这个过程中每个数据都可溯源,这是标识解析解决的非常重要的问题。
最后我想这样一个标识解析,对于文化元宇宙下一步的发展很有启发意义。我们认为文化元宇宙的核心要素就是三个:第一是数字身份,第二是数字货币,第三是数字资产。在这个过程中,如果把电视机作为元宇宙的入口,把电视机的机顶盒变成元宇宙的发射器,用刚才说的国际标准的标识符作为数字身份,而且国际注册机构已经授权中国公共关系协会文化大数据委员会作为中国区的注册机构,ISLI的DRA扮演元宇宙“户籍警”的角色。
数据身份认定之后,给个人机构以及对数据和内容都可以做标识,那整个元宇宙发展的“底座”就有了,不会像过去那样先发展后治理的模式。在这个基础上,我们就可以发展一种主权链。在中办国办文件里面明确提出推动标识解析与区块链、大数据等技术融合发展,在这个基础上依托我国主导的国际标准,它的手段就是依托国家文化大数据标识注册中心,实现这个标识解析体系和当下在发展的各种联盟链对接。用这样一套系统,给各个基于区块链的联盟链做背书,也就是说我们可以扮演一种公链的角色,从而推动整个区块链技术向前一步。
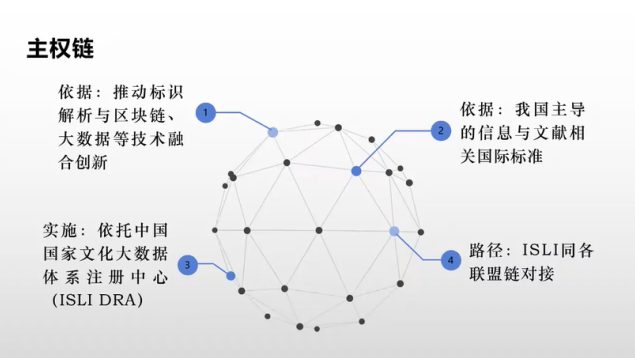
最后我建议我们在研究过程中,对文化元宇宙还是要考虑它的治理成本,千万不能再重蹈互联网“先发展、后治理”的覆辙,成本太高了。
推荐阅读




经典栏目
精彩专题
关注我们

大视频行业最具影响力的媒体社群平台,重要新闻、独家视频、深度评论分析,推动电视行业与各行各业的连接。

集合电视台、网络视听、潮科技等各种好玩信息。

专注于报道广电行业新鲜5G资讯,致力于成为广电行业有权威、有深度的5G自媒体平台。

UHD、4K、8K的最新资讯和最深入的分析,都在这里。

视频产业的专业圈子,人脉、活动、社区,就等你来。

我们只沉淀有深度的信息和数据。

致力于卫星电视信息、卫星通信技术、天地一体网络应用案例、以及广电、通信等产业的市场动态、政策法规和技术资讯的传播。













 关于我们
关于我们 诚聘英才
诚聘英才 商务合作
商务合作 中广圈子
中广圈子 意见反馈
意见反馈 关注我们
关注我们